1. Table of Contents
-
Implementation of SmoothQuant on Conv2d: ✅
-
Validation of the above implementation: ✅ (for $ \alpha = 0.5 $)
2. Implementation of SmoothQuant operation on Conv2d
- Get activation scale
- Get weight scale
- Compute smoothing factor $ s $ based on above two scales
- Apply scaling:
- $\text{input} \mathrel{{/}{=}} s$
- $\text{weight} \mathrel{{*}{=}} s$
2.1 Get activation & weight scale
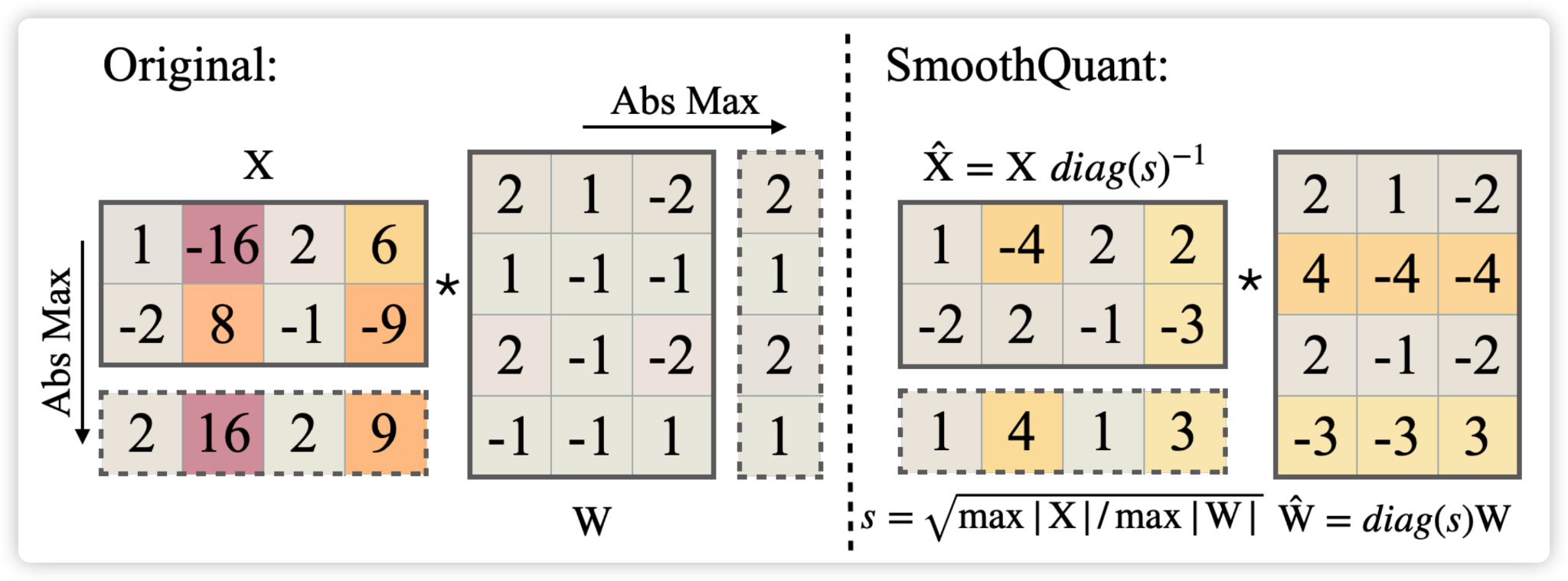
- Take a look at the shape of activation, output, and weight in Conv2d:
- Take one layer as an example:
- Input shape: torch.Size([4, 256, 182, 182])
- Weight shape: torch.Size([128, 256, 3, 3])
- Output shape: torch.Size([4, 128, 180, 180])
- The absMax value we get is per-channel according to SmoothQuant (above) -> Means that we should have 256 number of element (max value for each channel) for this layer of activation.
def register_collect_smoothquant_hook(model, data_loader, num_batch=200):
model.eval()
act_scales = {}
weight_scales = {}
def forward_hook(module, input, name):
hidden_dim_act = input[0].shape[1]
tensor_act = input[0].view(-1, hidden_dim_act).abs().detach()
comming_max_act = torch.max(tensor_act, dim=0)[0].float().cpu()
if name not in act_scales:
act_scales[name] = comming_max_act
else:
act_scales[name] = torch.max(act_scales[name], comming_max_act)
hidden_dim_weight = module.weight.shape[1]
tensor_weight = module.weight.view(-1, hidden_dim_weight).abs().detach()
comming_max_weight = torch.max(tensor_weight, dim=0)[0].float().cpu()
if name not in weight_scales:
weight_scales[name] = comming_max_weight
else:
weight_scales[name] = torch.max(weight_scales[name], comming_max_weight)
hooks = []
for name, module in model.named_modules():
if isinstance(module, torch.nn.Conv2d):
hook = module.register_forward_pre_hook(partial(forward_hook, name=name))
hooks.append(hook)
try:
with torch.no_grad():
for i, inputs in enumerate(tqdm(data_loader, desc='collecting stats', total=num_batch)):
if i >= num_batch:
break
load_data_to_gpu(inputs)
model(inputs)
finally:
for h in hooks:
h.remove()
return act_scales, weight_scales
- Input shape: torch.Size([4, 256, 182, 182])
- hidden_dim_act = 256
- Weight shape: torch.Size([128, 256, 3, 3])
- …
2.2 Compute smooth factor based on two scales
act_scales, weight_scales = register_collect_smoothquant_hook(model, test_loader, 200)
scales = {}
for name, act_scale, weight_scale in zip(act_scales.keys(), act_scales.values(), weight_scales.values()):
scale = torch.sqrt(act_scale / weight_scale)
scales[name] = scale.view(1, -1, 1, 1).to(device)
2.3 Apply scaling
- For activation, we use hook to modify the input everytime it comes to a Conv2d module:
def register_smoothquant_act_hook(model, scales):
def forward_pre_hook(module, input, name):
modified_input = input[0] / scales[name]
return (modified_input,)
handles = []
for name, module in model.named_modules():
if isinstance(module, quant_nn.Conv2d):
handle = module.register_forward_pre_hook(partial(forward_pre_hook, name=name))
handles.append(handle)
return handles
- For weight, we modify its value offline:
def register_smoothquant_weight_hook(model, scales):
for name, module in model.named_modules():
if isinstance(module, quant_nn.Conv2d):
with torch.no_grad():
module.weight *= scales[name]
return
3.1 Validation through amax value obtained by quantizer

3.2 Validation through accuracy comparison
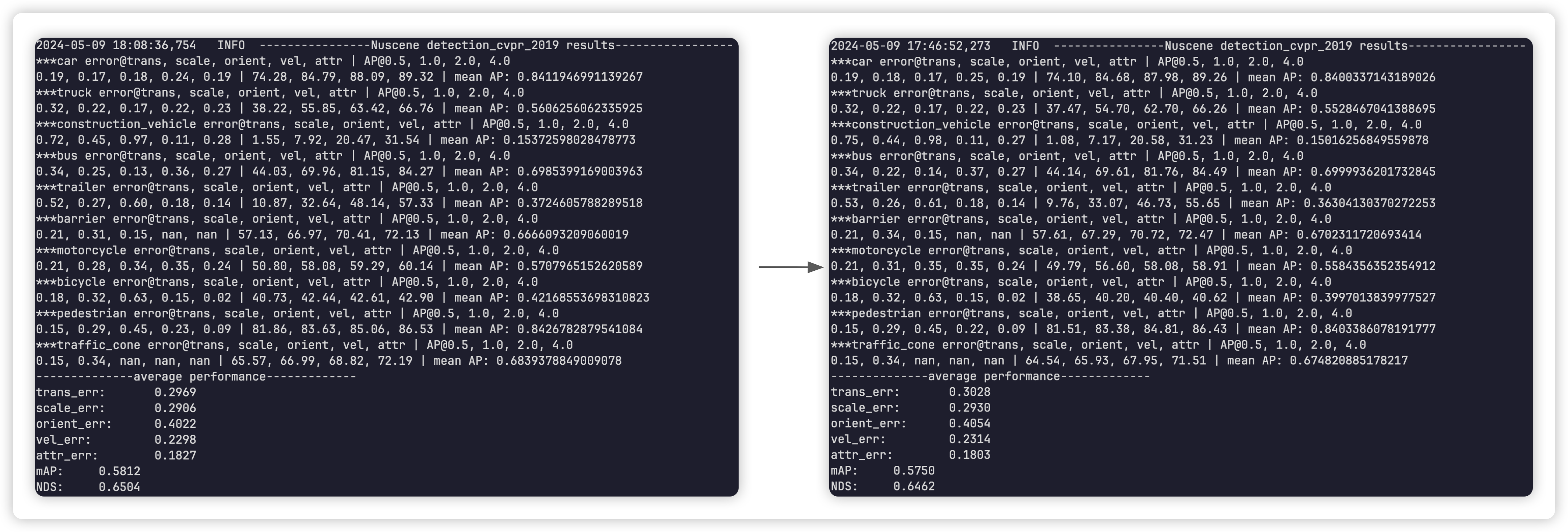
Thinking is that the way I get the absMax value may not be on the right track. Therefore:
4. What’s next?
- Try different scaling factor:
- Ranging from 0.05 to 0.95 (with the step of 0.05)
- Draw an accuracy graph respective to the change of scaling factor
- Check the way of getting absMax value
- Compute L1 loss of each layer of activation
- Visualize activation
- Increase calibration data number (200/1500)
- Dynamic scaling factor $ \alpha $