This is the official repo for Automatic Short Answer Grading (ASAG) project, named LLMarking, from Xi’an Jiaotong Liverpool University (XJTLU).
Using vLLM as the Large Language Model (LLM) inference framework and FastAPI as the HTTP service framework, this project can achieve high throughput of both LLM tokens delivered and request handling.
Feature
This project aims to achieve high concurrency automatic short answer grading (ASAG) system and implement the construction of service.
- Prompt-learning enables LLMs to handle downstream tasks even without fintuning. We implemented zero-shot, one-shot, and few-shot to test the performances of different LLMs.
- LoRA/QLoRA enables us to finetune to model with less GPU resources such as memory and computation capacity. This can be happening when continuous poor performances was witnessed even after trials of various prompt-learning.
- vLLM supports Continuous batching of incoming requests, using an extra thread for inferencing.
- vLLM provides abstracts of asyncio, using asyncio http framework after abstracts of uvicorn+FastAPI to achieve http api privision.
Supported models
Qwen/Qwen1.5-14B-Chat-GPTQ-Int4Qwen/Qwen1.5-32B-Chat-AWQinternlm/internlm2-chat-7b01-ai/Yi-1.5-9B-Chatmodelscope/Yi-1.5-34B-Chat-AWQCohereForAI/aya-23-8Bmeta-llama/Meta-Llama-3-8B-InstructTHUDM/glm-4-9b-chatQwen/Qwen2-7B-Instructgoogle/gemma-1.1-7b-itmistralai/Mistral-7B-Instruct-v0.3microsoft/Phi-3-small-8k-instructopenbmb/MiniCPM-2B-dpo-bf16
Getting Started
Requirements
IMPORTANT:
The requirement below is mandatory. And we’ve only tested our project on the following platform.
| Mandatory | Recommended |
|---|---|
| Python | 3.8 |
| CUDA | 12.1 |
| torch | 2.1 |
| einops | 0.8.0 |
| transformers | 4.41.0 |
| accelerate | 0.30.1 |
| vLLM | 0.4.3 |
| tiktoken | 0.6.0 |
| sentencepiece | 0.2.0 |
| scipy | 1.13.0 |
| FastAPI | 0.111.0 |
TIP:
Use
pip install -r requirement.txtto install all the requirement if you want to create a new environment on your own or stick with existing environment.
Quickstart
Repo Download
We first clone the whole project by git clone this repo:
git clone git@github.com:BiboyQG/ASAG.git && cd ASAG
Environment Setup
Then, it is necessary for us to setup a virtual environmrnt in order to run the project.
Currently, we don’t provide docker image or dockerfile, but instead we offer conda(Anaconda/Miniconda) environment config file inside env folder.
Therefore, you can simply copy and run the following in your terminal to quickly setup the environment:
NOTE:
You can rename
my_new_envto any name you want.
conda env create -n my_new_env -f env/environment.yml && conda activate my_new_env
Launch Server
Then we need to setup server-side to provide the service to the clients. To launch our HTTP server, simply:
python vllm_server.py -m [index of the model in the above list]
If you launch the server with the specific model you specify for the first time, the server would automatically download the model and save the files to .cache/huggingface/hub.
NOTE:
Some users may find it difficult to download model files from Huggingface due to internet issues. Hence, we provide the following solution.
For users that don’t have access to Huggingface, you need to do the following things:
- Import
snapshot_downloadfrommodelscopeinstead of fromhuggingface_hub:
from modelscope import snapshot_download
- Enable the use of
modelscopeby uncommenting this line of code withinvllm_server.py:
os.environ['VLLM_USE_MODELSCOPE']='True'
Request and Response
After that, we can either start the student entry or client side to pass our inputs to the server:
- For student entry:
NOTE:
0stands for using zero-shot prompt, while1for one-shot, and2for few-shot.
python student_entry.py -n [0, 1, 2]
- For casual client:
NOTE:
-sstands for get response in a streaming way, which is optional.
python student_entry.py [-s]
WebUI
After launching vllm_server, you can also run gradio_webui.py which is a webui based on gradio. This can achieve a chat-liked format like ChatGPT, which is more user-friendly.
python gradio_webui.py

Data and Results
-
Example data: example.json
-
Zero-shot pormpt template:
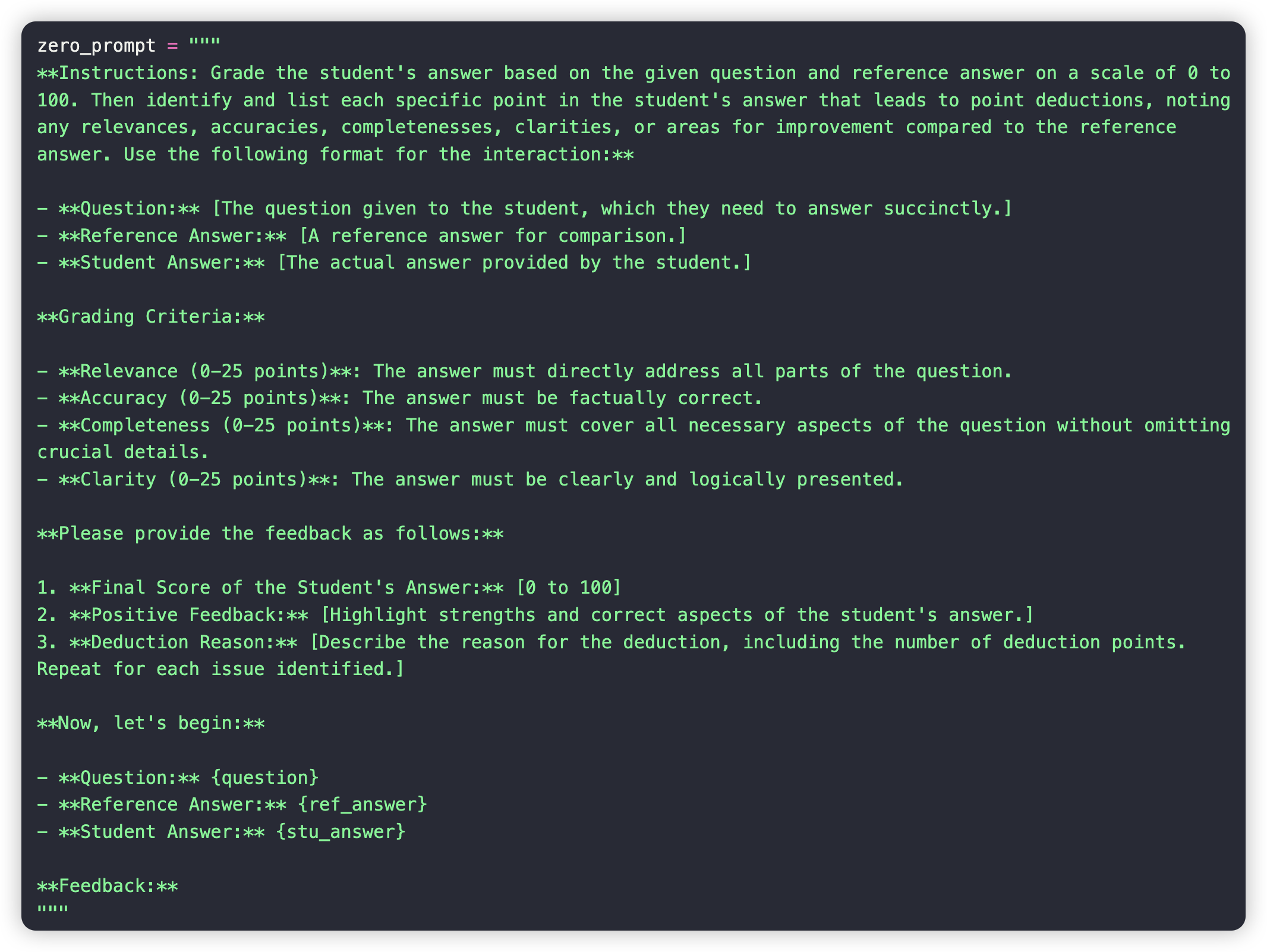
- Test on different LLMs with prompt template and example data: results.
Acknowledgement
- vllm_server.py referenced from vLLM official implementation - server.
- vllm_client.py referenced from vLLM official implementation - client.