Take mmdetection as an example
- First find the
Runnerclass:

This is the place where the build of the model is completed:
class Runner:
def __init__(...):
...
...
self.model = self.build_model(model)
# wrap model
self.model = self.wrap_model(
self.cfg.get('model_wrapper_cfg'), self.model)
# get model name from the model class
if hasattr(self.model, 'module'):
self._model_name = self.model.module.__class__.__name__
else:
self._model_name = self.model.__class__.__name__
...
...
- Learn about how
pytorch-quantizationworks by diving into its source code:
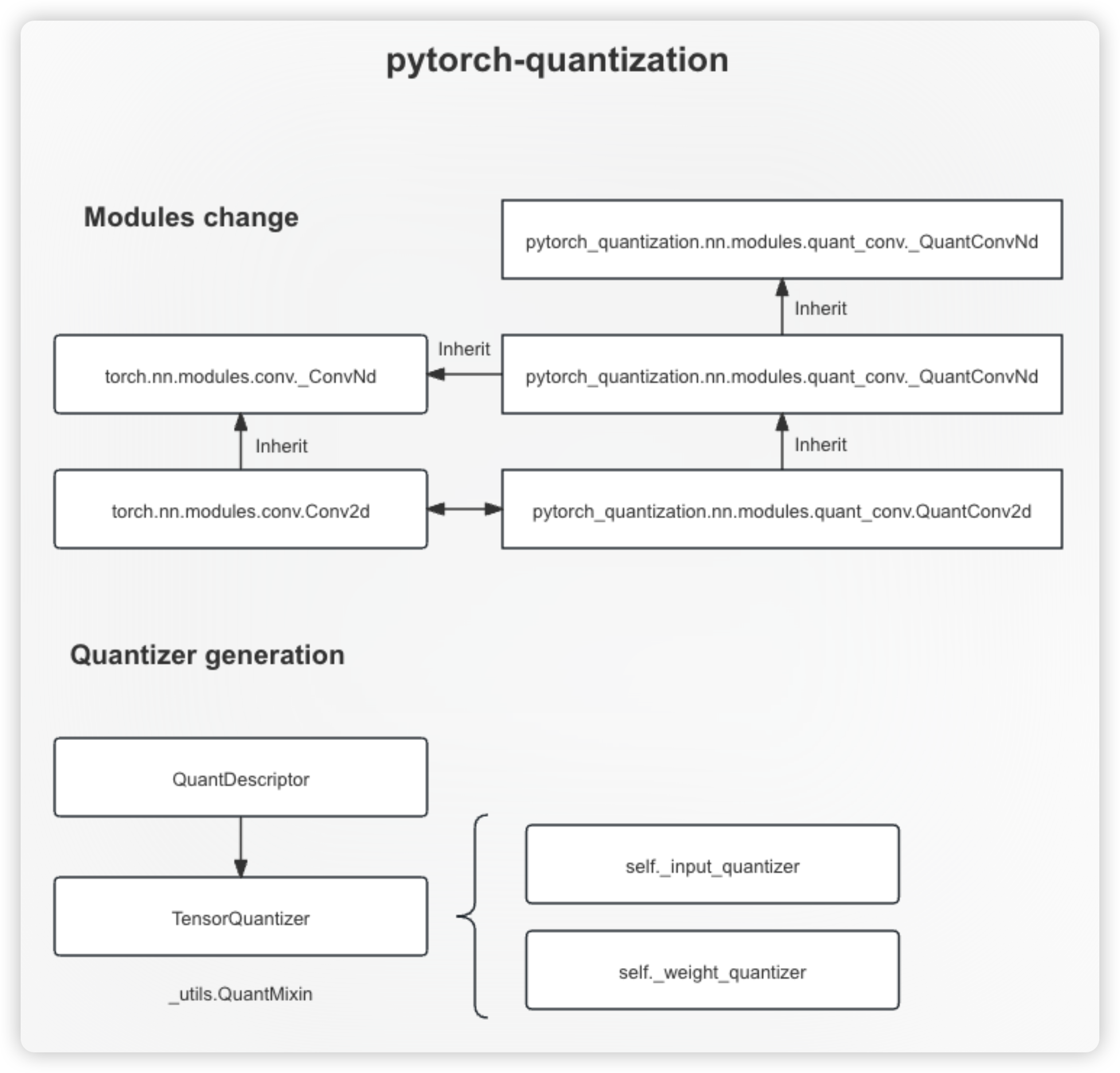
- Code about the quantization function respect to a specific Pytorch model as input:
quant_utils.py: a utils file to provide helper functions to ptq.py interfaces.
import torch
import re
import yaml
import json
import os
import collections
from pathlib import Path
from pytorch_quantization import quant_modules
from pytorch_quantization.nn.modules import _utils as quant_nn_utils
from pytorch_quantization import calib
from pytorch_quantization import nn as quant_nn
from pytorch_quantization.tensor_quant import QuantDescriptor
from absl import logging as quant_logging
def load_model(config, weight, device='cpu'):
pass
# intput QuantDescriptor: Max or Histogram
# calib_method -> ["max", "histogram"]
def initialize(calib_method: str):
quant_desc_input = QuantDescriptor(calib_method=calib_method)
quant_nn.QuantConv2d.set_default_quant_desc_input(quant_desc_input)
quant_nn.QuantMaxPool2d.set_default_quant_desc_input(quant_desc_input)
quant_nn.QuantLinear.set_default_quant_desc_input(quant_desc_input)
quant_logging.set_verbosity(quant_logging.ERROR)
def prepare_model(config, weight, device, calib_method):
# quant_modules.initialize() <- the method that automatically quantizes the model
initialize(calib_method)
model = load_model(config, weight, device)
model.float()
model.eval()
return model
def transfer_torch_to_quantization(nn_instance, quant_mudule):
quant_instance = quant_mudule.__new__(quant_mudule)
for k, val in vars(nn_instance).items():
setattr(quant_instance, k, val)
def __init__(self):
# Return two instances of QuantDescriptor; self.__class__ is the class of quant_instance, E.g.: QuantConv2d
quant_desc_input, quant_desc_weight = quant_nn_utils.pop_quant_desc_in_kwargs(self.__class__)
if isinstance(self, quant_nn_utils.QuantInputMixin):
self.init_quantizer(quant_desc_input)
if isinstance(self._input_quantizer._calibrator, calib.HistogramCalibrator):
self._input_quantizer._calibrator._torch_hist = True
else:
self.init_quantizer(quant_desc_input, quant_desc_weight)
if isinstance(self._input_quantizer._calibrator, calib.HistogramCalibrator):
self._input_quantizer._calibrator._torch_hist = True
self._weight_quantizer._calibrator._torch_hist = True
__init__(quant_instance)
return quant_instance
def quantization_ignore_match(ignore_layer, path):
if ignore_layer is None:
return False
if isinstance(ignore_layer, str) or isinstance(ignore_layer, list):
if isinstance(ignore_layer, str):
ignore_layer = [ignore_layer]
if path in ignore_layer:
return True
for item in ignore_layer:
if re.match(item, path):
return True
return False
# iterative method
def torch_module_find_quant_module(module, module_dict, ignore_layer):
for name in module._modules:
submodule = module._modules[name]
path = name
torch_module_find_quant_module(submodule, module_dict, ignore_layer)
submodule_id = id(type(submodule))
if submodule_id in module_dict:
ignored = quantization_ignore_match(ignore_layer, path)
if ignored:
print(f"Quantization : {path} has ignored.")
continue
# substitute the layer with quantized version
module._modules[name] = transfer_torch_to_quantization(submodule, module_dict[submodule_id])
def replace_to_quantization_model(model, ignore_layer=None):
module_dict = {}
for entry in quant_modules._DEFAULT_QUANT_MAP:
module = getattr(entry.orig_mod, entry.mod_name)
module_dict[id(module)] = entry.replace_mod
torch_module_find_quant_module(model, module_dict, ignore_layer)
def create_dataloader(dir, batch_size, is_train):
pass
def prepare_val_dataset(dir, batch_size, is_train=False):
dataloader = create_dataloader(dir, batch_size, is_train)
return dataloader
def prepare_train_dataset(dir, batch_size, is_train=True):
dataloader = create_dataloader(dir, batch_size, is_train)
return dataloader
def test(save_dir, model, dataloader):
pass
def evaluate(model, loader, save_dir='.'):
if save_dir and os.path.dirname(save_dir) != "":
os.makedirs(os.path.dirname(save_dir), exist_ok=True)
return test(save_dir, model, loader)
def collect_stats(model, data_loader, device, num_batch=200):
model.eval()
# Enable calibrator
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
module.disable_quant()
module.enable_calib()
else:
module.disable()
# test
with torch.no_grad():
for i, datas in enumerate(data_loader):
data = datas[0].to(device).float()
model(data)
if i >= num_batch:
break
# Disable calibrator
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
module.enable_quant()
module.disable_calib()
else:
module.enable()
def compute_amax(model, device, **kwargs):
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
if isinstance(module._calibrator, calib.MaxCalibrator):
module.load_calib_amax()
else:
module.load_calib_amax(**kwargs)
module._amax = module._amax.to(device)
# method parameter designed for "histogram", method in ['entropy', 'mse', 'percentile']
def calibrate_model(model, dataloader, device, method):
# Collect stats with data flowing
collect_stats(model, dataloader, device)
# Get dynamic range and compute amax (used in calibration)
compute_amax(model, device, method='mse')
def export_ptq(model, save_file, device, dynamic_batch=False):
input_dummy = ...(device)
quant_nn.TensorQuantizer.use_fb_fake_quant = True
model.eval()
with torch.no_grad():
torch.onnx.export(model, input_dummy, save_file, opset_version=13,
input_names=['input'], output_names=['output'],
dynamic_axes={'input': {0: 'batch'}, 'output': {0: 'batch'}} if dynamic_batch else None,
)
quant_nn.TensorQuantizer.use_fb_fake_quant = False
# To test if there's any quantized layer
def have_quantizer(layer):
for name, module in layer.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
return True
# Disable quantization (to a specific layer)
class disable_quantization:
# init
def __init__(self, model):
self.model = model
# Disable quantization
def apply(self, disabled=True):
for name, module in self.model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
module._disabled = disabled
def __enter__(self):
self.apply(disabled=True)
def __exit__(self, *args, **kwargs):
self.apply(disabled=False)
# Enable quantization (to a specific layer)
class enable_quantization:
def __init__(self, model):
self.model = model
def apply(self, enabled=True):
for name, module in self.model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
module._disabled = not enabled
def __enter__(self):
self.apply(enabled=True)
return self
def __exit__(self, *args, **kwargs):
self.apply(enabled=False)
# Saving log
class SummaryTool:
def __init__(self, file):
self.file = file
self.data = []
def append(self, item):
self.data.append(item)
json.dump(self.data, open(self.file, "w"), indent=4)
def sensitive_analysis(model, loader, summary_file):
summary = SummaryTool(summary_file)
# for loop to iterate every layer
print("Sensitive analysis by each layer....")
for i in range(0, len(list(model.modules()))):
layer = list(model.modules())[i]
# tell if layer has quantized layer
if have_quantizer(layer): # if so
# disable the layer
disable_quantization(layer).apply()
# calculate map
ap = evaluate(model, loader)
# save ap in json
summary.append([ap, f"model.{i}"])
# enable back the layer
enable_quantization(layer).apply()
print(f"layer {i} ap: {ap}")
else:
print(f"ignore model.{i} because it is {type(layer)}")
# after the iteration, print the top 10 worst quantized layer and save to log
summary = sorted(summary.data, key=lambda x: x[0], reverse=True)
print("Sensitive Summary: ")
for n, (ap, name) in enumerate(summary[:10]):
print(f"Top{n}: Using fp16 {name}, ap = {ap:.5f}")
summary.append([name, f"Top{n}: Using fp16 {name}, ap = {ap:.5f}"])
ptq.py: an interface that utilizes the helper/utils functions
import torch
import quant_utils as quantize
import argparse
def run_SensitiveAnalysis(config, weight, dir, calib_method, hist_method, device):
# prepare model
print("Prepare Model ....")
model = quantize.prepare_model(config, weight, device, calib_method)
quantize.replace_to_quantization_model(model)
# prepare dataset
print("Prepare Dataset ....")
train_dataloader = quantize.prepare_train_dataset(dir, args.batch_size, is_train=True)
val_dataloader = quantize.prepare_val_dataset(dir, args.batch_size, is_train=False)
# calibration model
print("Begining Calibration ....")
quantize.calibrate_model(model, train_dataloader, device, hist_method)
# sensitive analysis
print("Begining Sensitive Analysis ....")
quantize.sensitive_analysis(model, val_dataloader, args.sensitive_summary)
def run_PTQ(args, device):
# prepare model
print("Prepare Model ....")
model = quantize.prepare_model(args.config, args.weights, device, args.calib_method)
quantize.replace_to_quantization_model(model, args.ignore_layers)
# prepare dataset
print("Prepare Dataset ....")
val_dataloader = quantize.prepare_val_dataset(args.cocodir, batch_size=args.batch_size, is_train=False)
train_dataloader = quantize.prepare_train_dataset(args.cocodir, batch_size=args.batch_size, is_train=True)
# calibrate model
print("Beginning Calibration ....")
quantize.calibrate_model(model, train_dataloader, device, args.hist_method)
summary = quantize.SummaryTool(args.ptq_summary)
if args.eval_origin:
print("Evaluate Origin...")
with quantize.disable_quantization(model):
ap = quantize.evaluate(model, val_dataloader)
summary.append(["Origin", ap])
if args.eval_ptq:
print("Evaluate PTQ...")
ap = quantize.evaluate(model, val_dataloader)
summary.append(["PTQ", ap])
if args.save_ptq:
print("Export PTQ...")
quantize.export_ptq(model, args.ptq, device)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--config', type=str, default='configs/...', help='model config file')
parser.add_argument('--weights', type=str, default='', help='initial weights path')
parser.add_argument('--dir', type=str, default="dataset/...", help="dataset directory")
parser.add_argument('--batch_size', type=int, default=8, help="batch size for data loader")
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--hist_method', type=str, default='mse', choices=['entropy', 'mse', 'percentile'], help='histogram calibration methods used in histogram, one of ["entropy", "mse", "percentile"]')
parser.add_argument('--calib_method', type=str, default='histogram', choices=["max", "histogram"], help='calibration methods used in histogram, one of ["max", "histogram"]')
parser.add_argument('--sensitive', type=bool, default=True, help="use sensitive analysis or not before ptq")
parser.add_argument("--sensitive_summary", type=str, default="sensitive-summary.json", help="summary save file")
parser.add_argument("--ignore_layers", type=str, default="model\.105\.m\.(.*)", help="regx")
parser.add_argument("--save_ptq", type=bool, default=False, help="file")
parser.add_argument("--ptq", type=str, default="ptq_centerpoint.onnx", help="file")
parser.add_argument("--eval_origin", action="store_true", help="do eval for origin model")
parser.add_argument("--eval_ptq", action="store_true", help="do eval for ptq model")
parser.add_argument("--ptq_summary", type=str, default="ptq_summary.json", help="summary save file")
args = parser.parse_args()
is_cuda = (args.device != 'cpu') and torch.cuda.is_available()
device = torch.device("cuda:0" if is_cuda else "cpu")
# sensitive analysis
if args.sensitive:
print("Sensitive Analysis....")
run_SensitiveAnalysis(args.config, args.weights, args.dir, args.calib_method, args.hist_method, device)
# PTQ
# ignore_layers= ["model\.105\.m\.(.*)", model\.99\.m\.(.*)]
# args.ignore_layer = ignore_layers
print("Beginning PTQ.....")
run_PTQ(args, device)
print("PTQ Quantization Has Finished....")
It can be noted that three functions in the quant_utils.py are not implemented:
-
def load_model(config, weight, device='cpu'): pass -
def create_dataloader(dir, batch_size, is_train): pass -
def test(save_dir, model, dataloader): pass
This is because MMDetection3D is well-encapsulated:
def main():
...
...
if 'runner_type' not in cfg:
# build the default runner
runner = Runner.from_cfg(cfg)
else:
# build customized runner from the registry
# if 'runner_type' is set in the cfg
runner = RUNNERS.build(cfg)
# start testing
runner.test()
And in the test function:
class Runner:
...
...
def test(self) -> dict:
"""Launch test.
Returns:
dict: A dict of metrics on testing set.
"""
if self._test_loop is None:
raise RuntimeError(
'`self._test_loop` should not be None when calling test '
'method. Please provide `test_dataloader`, `test_cfg` and '
'`test_evaluator` arguments when initializing runner.')
self._test_loop = self.build_test_loop(self._test_loop) # type: ignore
self.call_hook('before_run')
# make sure checkpoint-related hooks are triggered after `before_run`
self.load_or_resume()
metrics = self.test_loop.run() # type: ignore
self.call_hook('after_run')
return metrics
...
...
In self.build_test_loop(self._test_loop):
class Runner:
...
...
def build_test_loop(self, loop: Union[BaseLoop, Dict]) -> BaseLoop:
"""Build test loop.
Examples of ``loop``::
# `TestLoop` will be used
loop = dict()
# custom test loop
loop = dict(type='CustomTestLoop')
Args:
loop (BaseLoop or dict): A test loop or a dict to build test loop.
If ``loop`` is a test loop object, just returns itself.
Returns:
:obj:`BaseLoop`: Test loop object build from ``loop_cfg``.
"""
if isinstance(loop, BaseLoop):
return loop
elif not isinstance(loop, dict):
raise TypeError(
f'test_loop should be a Loop object or dict, but got {loop}')
loop_cfg = copy.deepcopy(loop) # type: ignore
if 'type' in loop_cfg:
loop = LOOPS.build(
loop_cfg,
default_args=dict(
runner=self,
dataloader=self._test_dataloader,
evaluator=self._test_evaluator))
else:
loop = TestLoop(
**loop_cfg,
runner=self,
dataloader=self._test_dataloader,
evaluator=self._test_evaluator) # type: ignore
return loop # type: ignore
...
...
…… so since this week’s focus is on writing the PTQ API (above),
By next week:
- get model, dataloader definition (just need some more time).
- or switch to
OpenPCDetfor simplicity.